

研究の背景
今日、Web上では、従来のユーザ発信コンテンツ(CGM:Consumer Generated Media)に加え、ブログやチャットなどネットワークを介して行われるユーザ同士のコミュニケーションの記録、オンラインショッピングやライフログのような人々の生活の記録、さらにセンサ等によって取得された時々刻々と変化する環境情報など、実に様々な情報が配信されています。今や、Webは、社会や環境の活動を反映した膨大な情報の記憶媒体(social memory)としての役割を果たしています。これらの膨大なデータを総合的に分析しながら、潜在的な法則性を発見したり、様々な分野や組織で個別に蓄積されてきた情報を横断的に連結・統合したりすることで、世界規模の知識ネットワークを構築し、様々な社会問題や環境問題を解決できるようになると考えられます。私たちは、Webをより知的な情報獲得と分析の環境へと進化させることを目的として、次世代Web基盤「ナレッジクラスタシステム」の研究開発を行っています。
相関分析による「つながり」の発見
ナレッジクラスタシステムは、ナレッジGRID基盤*1と相関分析エンジンによって構成されます。従来のWebのようにデータを配信・共有するだけでなく、特定のデータを意図的に集めたり、集めたデータの中から様々な話題や出来事に関する情報を抽出したり、抽出した情報を様々につなぎ合わせたり、つなぎ合わせられた情報を検索したり閲覧したりする機能を備えています。例えば、地球気候変動と治安問題のつながり(相関関係: correlation)を知りたい場合、従来の検索エンジンでは“地球気候変動 治安問題”というキーワードを含むWebページを検索し、検索結果の内容をユーザが直接自分で判断するしかありませんでした。一方、私たちが開発しているナレッジクラスタシステムは、同じ質問に対し、例えば「この数年、北アフリカで異常高温と水紛争が頻発している」というような、キーワードで直接指定されていない内容にまで範囲を広げて相関のある情報を見つけ出すことができます。
相関分析エンジンを使って、Webページはもちろん、ニュース配信や気象観測データまで多岐にわたる大量のデータを対象に、それらの意味的なつながりと時空間的なつながりのあるデータを発見します。その際、従来のように、辞書や時空間関係を予め指定する必要がないため、異種・異分野のデータの相関も拡張性高く発見することができます。相関分析エンジンは、時間、空間、主題に関する様々な種類の特徴量を使ってデータを索引付け、問い合わせ処理の際は、相関を発見するのに最適な特徴量の組み合わせ(相関の文脈と呼びます)と、それらを用いて高い相関を示すデータ集合を同時に検索します。その結果、先程の例のように、「この数年(時間の特徴量)、北アフリカで(空間の特徴量)異常高温と水紛争が(主題の特徴量)頻発している」という文脈の中で高い相関を示すデータ集合を発見することができます。私たちは、意味空間モデルとMoving Phenomena時空間モデルによる相関分析手法を提案しており、いずれも多次元空間における部分空間選択により最適な特徴量の組み合わせと相関データ集合を柔軟性高くかつ効率的に見つけ出すことができることが特徴です。
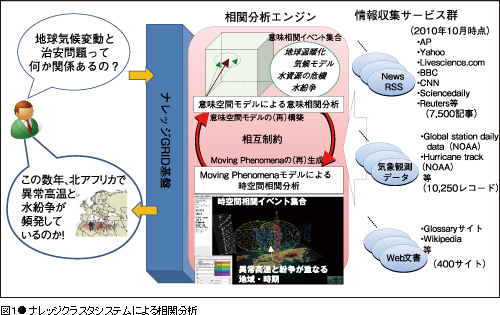
ナレッジGRID基盤
ナレッジクラスタシステムの全ての機能は、ナレッジGRID基盤の上に実装されています。アジアやヨーロッパなど世界中の拠点をつないだ広域GRIDネットワークを構築し、その上にサービス指向アーキテクチャに基づいたサービスコンピューティング環境*2を実現しています。ナレッジGRID基盤上には、データ収集と情報抽出、相関分析、ユーザインタフェース・インタラクションに関する多種多様なソフトウェアサービスが、各拠点で並行して開発され配備されています。これらのサービスを組み合わせ連携させることで、様々な次世代Webアプリケーションを実現することができます。これまでに、Webをハイパーリンクとは無関係に相関関係に沿って閲覧する“Link-free Web Browsing”、場所や時期、テーマに応じて相関性のある情報を次々と推薦する観光案内システム、企業や組織の製品・サービス・技術に関する情報をWebサイトや特許から幅広く収集し、様々なテーマの下でマッチメイキングを行うパートナーシップマネジメントシステムなど、様々なアプリケーションを開発してきました。ナレッジGRID基盤は、アプリケーション開発のためのサービス連携機構と開発言語を提供しています。また、アプリケーションでの使われ方に基づいて役立つサービスを検索する機構(サービス発見エンジン)の研究開発も行っています。
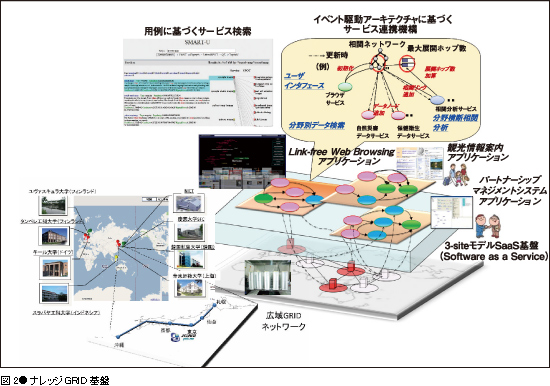
今後の展望
eScienceやデータ中心科学は、実験科学、理論科学、計算科学に次ぐ第四の科学と言われ、様々な分野にわたる大量のデータを分析することで潜在的に存在する法則性や関連性を発見・検証する科学です。社会的必要性を重視し、これまでの科学的探究により得られた知見を実社会での意思決定や行動支援に生かすことを目的に、科学関連のデータと社会関連のデータの相関を応用指向で発見します。例えば、「太陽活動と経済活動には相関があるのか?」というような質問を扱います。このような質問に対しては、従来のような科学的モデルの構築が困難なため、ナレッジクラスタシステムのように異種・異分野のデータの相関を柔軟かつ拡張性高く発見する技術が有効に働くことが期待されます。現在、「分散情報処理基盤における横断的データマネージメントサービスの研究開発」プロジェクトにおいて、宇宙・地球環境の科学データと新聞記事などの社会データを対象に研究開発を進めています。
一方、ナレッジGRID基盤は、新世代ネットワークにおける「価値を創造するネットワーク」サービス連携基盤としての展開を進めています。従来のサービスコンピューティングのパラダイムを拡張し、サーバ、ストレージ、ネットワーク、端末から、ソフトウェア、通信手段、人手処理まで含むあらゆるICT資源をサービスとして抽象化し、ネットワークの制約を意識することなくシームレスにサービス連携が可能になる技術の開発に取り組んでいます。また、サービス連携を構成する要素技術(サービス・アドレッシング、メッセージング、サービス発見、協調制御など)を、ネットワーク基盤上にダイレクトに実装することで、サービス同士の水平連携やサービスとICT資源間の垂直連携を、高いパフォーマンスとスケーラビリティで実現する方法の開発にも取り組んでいます。
謝辞
本研究プロジェクトを遂行するにあたり、慶應義塾大学環境情報学部 清木 康教授には多大なご助言およびご指導を賜りました。ここに記して謝意を表します。
用語解説
- *1 GRID基盤
ネットワーク上に分散する計算資源やストレージ資源を相互に結びつけ、ひとつの複合した計算機システムを構成する技術であり、専用のミドルウェアによって実現される。大規模高速計算(HPC)や、物理的・組織的な枠を越えた資源の共有や管理(仮想組織(VO))に利用されている。 - *2 サービス指向アーキテクチャ
ソフトウェア工学の一手法で、各種情報システムやソフトウェアをサービスとして定義・実装し、ネットワークを介してサービスを連携させることで、大規模な情報システムを素早くかつ柔軟に構築できるようにする。これを実現するためのミドルウェア技術が、サービスコンピューティング環境である。

- 是津 耕司(ぜっつ こうじ)
- 知識創成コミュニケーション研究センター 知識処理グループ 主任研究員
- 1992年東京工業大学工学部情報工学科卒業。2005年京都大学大学院情報学研究科博士課程了。
博士(情報学)。1992年日本IBM入社。2003年通信総合研究所(現NICT)専攻研究員、2005年NICT研究員を経て、2007年より現職。データベース、情報検索、Webマイニングに興味を持つ。