| |  |
| | |
 |
||||||||||||||||||||||||||
| 馬 青 | ||||||||||||||||||||||||||
|
みなさん、ワープロで「せんせいになった」を入力してスペースキーを押してみてください。すると、大抵「先生になった」が表示されます。しかし、なぜ「先生になった」であって、「先生担った」にはならないのでしょうか。そう、我々人間にとってはその理由は極めて単純--「先生担った」は正しい日本語ではないからなのです。でも、ワープロにそれを分かってもらうのはそう簡単なことではありません。 ワープロは、「せんせいになった」が入力されると、どこからどこまでが一つの単語か分からないので、まずそれを正しく語単位に分解しなければなりません。そのために、単語辞書を用いて分解を行います。すると、「先生/に/なった」と「先生/担った/」という2通りの答えが得られます。それから、「担った」は他動詞で、その前に格助詞「を」がないといけないというチェックを入れます。すると、2番目の答えが排除されます(実際はダイナミックプログラミングと呼ばれる手法を用い、その2段階の処理を交互に行なうのが普通)。ワープロはこのような解析過程を経て始めて「せんせいになった」から「先生になった」へと正しく仮名漢字変換ができるのです。このように、形態素(分解された最小単位)の属性(品詞、活用など)を解析しながら文を正しく分解していくことを「形態素解析」と呼びます。これはもちろんワープロに限られた話しではなく、言葉を解析していく上で、どうしても経なければならない基本過程なのです。形態素解析の結果の例を表に示します。 |
||||||||||||||||||||||||||
表 形態素解析の例:「先生になった」
|
||||||||||||||||||||||||||
|
上にも述べたように形態素解析においては形態素の属性が重要な役割を演じています。属性の中には、例えば活用形や活用型などのように曖昧性が少なく単語辞書を調べるだけで済むものもあれば、品詞のように文脈によって変わるためそう簡単には決められないものもあります。特に英語や中国語などには動詞にも名詞にも使われるような多品詞語が非常に多くあります。例えば、有名な例として“Time flies like an arrow.”という文があります。fliesには飛ぶという動詞の他に蝿という名詞もあります。likeには動詞と前置詞があります。従って、英語などの形態素解析では多品詞語に対する品詞の決定(品詞付け)が一番の問題となります。 品詞付けに関する研究は自然言語処理研究を始めた頃から行なわれてきており、ルールベースや統計手法を主流とする数多くの品詞付けシステムが提案されてきました。しかし、それらのシステムはいずれも高い精度を出すために大量の答え付き訓練データ(例えば、英語の場合百万オーダー)を必要とします。実際、これだけの量の答え付き訓練データを用意することはそう簡単なことではありません。そこで、我々の知的機能研究室では神経回路網モデルを用いることによって、訓練データ(数万オーダー)が少なくても十分実用的に品詞付けできるシステムを開発しました。 神経回路網モデルはある特定のパターンの刺激に対してある特定の出力をするように学習させたシステムのことで、その働きが脳の神経回路網の働きと似ていることからそう名付けられました。まず、図のような入力層、中間層、出力層の三層からなるニューロンと呼ばれるノード群を用意します。各層のノードは上下の層のすべてのノードとリンクでつながっています。次に、最下層から各単語に対応する刺激をパターンとして各ノードに与え、そのときに最上層のノードが特定の品詞に対応したパターンで発火(活性化)するようにリンクの重みを調節します。ここまでが学習の過程に当たります。解析するときには、最下層のノードに各単語に対応するパターンを与えます。すると、そのパターンがリンクの重み付けのときに受けた刺激と似ている場合に、最上層のノードで特定の品詞に対応するパターンが発火します(ここで、○は発火しているノード、●は発火していないノードを表します)。図に挙げた神経回路網モデルは、「に」に対して、品詞「格助詞」が出力されている様子を表します。このとき、「に」とともにそのまわりの単語「先生」、「なった」も刺激パターンとして入力層に与えられます。出力層では複数の可能性(数量詞、格助詞、。。。)のうち「格助詞」に相当するノードが発火します。 |
||||||||||||||||||||||||||
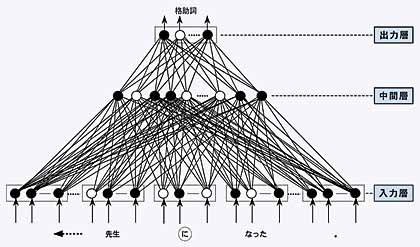 図 神経回路網モデルを用いる品詞付け |
||||||||||||||||||||||||||
|
このシステムの特徴の一つは状況に応じてどこまでまわりの単語を考慮すべきかが自動的に決まることです。もう一つの特徴は、入力を構成する各形態素(「先生」、「に」、「なった」)は品詞付けのとき同じように影響するのではなく、目標単語の影響度がもっとも高く、目標から遠くなっていくに従ってその影響度が減っていくように、自動的に重み付けできることです。実際、神経回路網モデルを用いた手法の最大のセールスポイントは学習によって調節しなければならない部分が格段に少ないことです。それは、必要な訓練データも少なくてよいことを意味します。従って、神経回路網モデルを用いればデータがまだあまり整備されていない国の言語に対しても高い精度で品詞付けすることができます。言語データの整備が始まったばかりであるタイ語に対し行なった実験では数万オーダの少量のデータで学習させたにもかかわらず我々の神経回路網モデルを用いた手法は統計手法より遥かに高い精度(94.4%)で未訓練データを品詞付けできました。 但し、神経回路網モデルを用いた手法は統計的手法と同じく、「統計的」に解析を行なうもので、「確実」な規則を取り扱うのが難しいという面があります。例えばある単語の品詞が一つ前の単語のみによって「確実」に決まると仮定しましょう。この場合でも、神経回路網モデルはあくまでもまず文脈全体の下での可能性に基づいて「統計的」に解析を行ないます。その結果、前の単語が同じでも全体の文脈が変わると、品詞付けの結果が変わってしまう可能性が出てきます。神経回路網モデルのこのような弱点を補うために、我々は更に学習困難とされる規則をも訓練データから自動獲得し、それを後処理に導入して神経回路網モデルとルールベースの統合システムの構築を試みました。計算機実験の結果、書き換え規則を後処理に用いることによって神経回路網モデルによる品詞付けのエラーは19.1%も減少(従って、精度が95.5%まで向上)しました。我々のシステムはほぼ実用的に使えるレベルに達したと言えます。 (知的機能研究室)
|
||||||||||||||||||||||||||
 | ||||||||||||||||||||||||||
|
|
|
|
||||||||||||||||||||||||
 次世紀の光技術開発を目指し、CRL国際シンポジウムを開催
独立行政法人化に向けた所内検討会
新規採用者の自己紹介
研究発表会のお知らせ
人事異動情報(抜粋) 次世紀の光技術開発を目指し、CRL国際シンポジウムを開催
独立行政法人化に向けた所内検討会
新規採用者の自己紹介
研究発表会のお知らせ
人事異動情報(抜粋)
|
||||||||||||||||||||||||||