


2002年より通信総合研究所(現 情報通信研究機構)の自然言語グループに属し、大規模コーパスからの言語情報の自動抽出に 取り組む。博士(工学)
インターネット検索エンジンの普及により、一般ユーザにも情報検索や情報抽出が身近なものになりました。これらを 支えるために自然言語処理の分野で広く研究され、さらなる精度向上を目指して、継続して研究が進められています。 情報検索とは、たとえば、インターネットで「紅葉狩りの名所」と入力すると、紅葉狩りの名所に関して書かれたWebページを 列挙して出力する、「ネット検索」がこれに当てはまります。一方、情報抽出とは、「紅葉狩りの名所」と入力されると、 紅葉狩りの名所とその名所の住所など、指定した事柄に関する情報を整理して出力することをいいます。どちらの技術でも、 対象となる文書中のテキストの解析が必要になりますが、利用している辞書に登録されていない、新しく生み出された用語が テキストに含まれると、解析がうまくいかないことが多くあります。この未だ辞書に登録されていない、新しく生み出された 用語を「新語」と呼びます。インターネット上では日々新語が生み出されており、これが検索や抽出の精度を下げる原因と なっています。このため、新聞記事などを用いて新語を獲得する研究が行われています。ところが、新聞記事とは違って、 Webページは同じ内容であっても、異なった表記、たとえば、「コンピュータ」が「コンピューター」と記述されていたりと、 書き手によってさまざまなため、効率的に新語を自動獲得することは容易ではありませんでした。
また、情報抽出に新語を利用するためには、その用語が人名や組織名なのか、ある専門分野に特化した用語なのかといった 属性を判別する必要があります。用語が持つ属性が情報を整理するための手がかりとなるからです。しかし、属性を自動的 かつ高精度に判別することは困難でした。
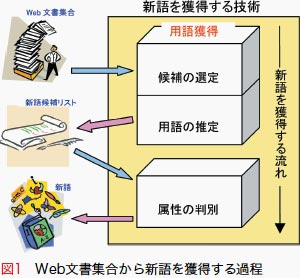
こうしたことから、自然言語グループでは、Web文書集合から新語を抽出し、その新語の属性を判別する技術を開発しました *1)。 この技術は大きく分けて、Web文書集合から用語を獲得する技術と、その用語の属性を判別し、新語として登録する技術の 二つからなります(図1)。本稿では、Web文書集合から用語を獲得する技術(用語獲得)を紹介します。
*1) この技術は、けいはんな情報通信オープンラボにおける沖電気とNICTの共同研究の成果の一つです。

本技術は、形態素列を対象として、用語獲得を行います。形態素とは、文を構成する語の最小単位のことで、文は形態素列と 捉えることができます。たとえば、「秋は紅葉狩り。」という文は、「秋/は/紅葉/狩り/。」のように5つの形態素からなる 文と解析されます。 ここでは句点「。」も、一つの形態素と考えます。この文中の連続する形態素を考えた場合、たとえば長さ2の形態素列は、 「秋/は」、「は/紅葉」、「紅葉/狩り」、「狩り/。」となります。
用語獲得は「候補の選定」と「用語の推定」の2段階で行います(図1)。まず、文書集合中の長さ1から5までの形態素列すべてを 対象として、多くの文書に使われていて、いくつかの文書の中では繰り返し使われている形態素列を、統計的指標を用いて、 候補として選定します。この方法で、人間が知らない用語を認識し、理解する感覚を、計算機に持たせました。次に、 候補を構成する形態素間の連接の強さを測ることで、その候補が用語かどうかを推定します。図2は「お/台/場」が用語で あるかどうかを推定するイメージです。もし「お/台/場」が用語であるなら、文書集合中の「お/台/場」に続く形態素の種類は、 形態素「場」を削った「お/台」や形態素「お」を削った「台/場」に続く形態素の種類よりも多いという仮説を統計的指標で 検証することで、「お台場」を用語と推定します。この方法で、人間が一部を聞いただけで、残りの内容を予測するような 感覚を計算機に持たせました。
図3は、ある大学の工学部のWebサイトから収集した文書集合から実際に本技術で獲得した用語の一部です。これまでに、一つ の名詞や、複数の名詞を繋げた複合名詞を用語として獲得する手法は多く提案されています。このような手法は獲得した用語の 確実性は高いのですが、テキストの自動解析の誤りによって分解された用語を獲得することはできません。これに対して、 本技術では、解析を誤って細かく分割されてしまった用語も獲得することができます。さらに、名詞や複合名詞に限らず、 全ての形態素列を対象とするため、論文のタイトルのような、動詞や助詞を含む長い名詞句も獲得できます。
本技術は、実用システムへの導入を考慮し、処理の高速化を目指しました。従来、用語の候補を選定する対象は文字列 でしたが、対象を形態素列にすることで、処理時間を短縮しています。現在、新聞記事2年分弱に相当する、テキストで 200メガバイトの収集済みのWebページ、1億文字の文章から用語獲得し、その用語の属性判別までの処理を平均1日で完了 します。これにより、1ヶ月おきに特定のドメインのWebページを対象に用語を獲得するといったことが可能となります。 そして、獲得・判別された用語は、検索および抽出システムの精度向上のために利用することができます。
現在、産学連携支援ツールBluesilk *2) に搭載された検索支援の機能を強化するために、本技術の導入が進められています。 今後、さらに用語獲得性能を改善し、他の実用システムへの導入を目指します。
自然言語グループでは、このように言語情報処理の基盤技術の研究を行い、それを用いた実用システムを開発することによって、 コンピュータやインターネットを人間にとって、もっと使いやすいものにすることを目指していきます。
*2) Bluesilk は(株)三菱総合研究所の登録商標です。

