









辞書を創る。それは膨大な言葉の海をすくい上げるような研究だ。果てしもないような作業だが、テキストデータを強力なマシンで処理することで、その可能性が見えてきた。
膨大な言語の収集・データ化が極めて重要
―言語の研究プロジェクトでは現在どのような研究が進められているのでしょうか。
 鳥澤現在、私達は「MASTARプロジェクト」という音声・言語処理分野の研究開発を包括的に推進するプロジェクトを進めています。このプロジェクトは、研究者やプログラマーなど、様々な役割を持った方々で構成され、多くの方の協力を得て取り組んでいます。この中には3つのグループがあり、1つは音声認識・音声対話、ユビキタスなインターフェースなどを研究する音声コミュニケーショングループ。2つ目は言語翻訳グループで、機械翻訳に集中しています。そして3つ目が私のいる言語基盤グループ。これは言語処理のとても基礎的な分野の研究ですが、「言語資源」というものを作ることが狙いのグループです。
鳥澤現在、私達は「MASTARプロジェクト」という音声・言語処理分野の研究開発を包括的に推進するプロジェクトを進めています。このプロジェクトは、研究者やプログラマーなど、様々な役割を持った方々で構成され、多くの方の協力を得て取り組んでいます。この中には3つのグループがあり、1つは音声認識・音声対話、ユビキタスなインターフェースなどを研究する音声コミュニケーショングループ。2つ目は言語翻訳グループで、機械翻訳に集中しています。そして3つ目が私のいる言語基盤グループ。これは言語処理のとても基礎的な分野の研究ですが、「言語資源」というものを作ることが狙いのグループです。
この、MASTARプロジェクトを音声・言語資源に関する研究開発の世界的拠点にしようと思っています。
―「言語資源」とは、どのようなものなのでしょうか。
鳥澤「言語資源」とは主として2種類のデータをさす言葉です。1つ目は人が書いたテキストそのもののデータで、「コーパス」と呼んでいます。もう1つはいわゆる「辞書」ですが、一般に言語処理の分野で辞書といった場合には、普通の本屋さんでは手に入らないような多種多様な辞書を指します。
コーパスについてですが、そもそも言語というのは非常に複雑な対象です。90年代初めくらいまでは、言語を処理するためにはプログラムを書けば何とかなるのではないかと、せっせとプログラムを書いていました。しかし、実用になるようなシステムはできませんでした。
ところが、複雑な対象を扱うときの1つのアプローチとして、膨大なデータの統計的な性質を使うという手法があることに気がついた人達がいました。そういう人達が、テキストデータ、つまり、コーパスを統計的に処理すれば、いろいろと面白いことが可能であることを示したわけです。
―それで膨大な言語、テキストの収集が始まるわけですね。
鳥澤そうなのですが、90年代初めまでは、統計を取るための大規模なデータ、つまりコーパスがなかなか手に入らなかった。しかし、少しずつそうしたコーパスを作り始めた人達がいて、統計的なアプローチで言語処理の性能がかなり上がることが分かってきた。
―大規模なデータは、どのように集めたのでしょうか。
鳥澤当初は新聞社に新聞何十年か分のデータを研究用に安く提供してもらい、これをコーパスとして研究していたのです。ところが、2000年代に入ってからWebが出てきて、桁違いに大量のデータが簡単に入手できるようになりました。コーパスは、統計処理しますので大きければ大きいほど良く、これを作ることが非常に大事になってきました。そして、それを使っていろいろ面白いことができるのです。
―具体的に開発している言語資源にはどんなものがあるのでしょうか。
鳥澤主に3つあります。1つ目は「対訳コーパス」という機械翻訳の能力を上げるためのものがあります。例えば、われわれの隣で研究をしている言語翻訳グループの技術を使うと、どう翻訳するかを統計的処理によって自動的に学習し、それを多言語に翻訳できます。そのための統計処理に必要なのが対訳コーパスです。我々は言語翻訳グループと共同で、対訳コーパスの作成や産業界への配信を行っています。
2つ目は「概念辞書」といって、私達がいま精力的に取り組んでいて、新たな言語を使ったサービス、ツールで活用できるものとしての普及にも期待しているものです。この2つと、音声コミュニケーショングループが開発している音声データとテキストデータであるコーパスを組み合わせた「音声言語コーパス」の合計3種類の言語資源を、「ALAGIN(アラジン:高度言語情報融合フォーラム)」(※)の皆さんに提供しているところで、これには一般の企業で商用サービスを始めてもらおうという意図もあります。
(※)高度言語情報融合フォーラム(ALAGIN―Advanced Language Information Forum)。会長・辻井潤一東京大学教授。MASTARプロジェクトの開始に伴い、産学官の連携により研究開発と成果の普及展開を進めるために2009年3月に発足したフォーラム。言語の「壁」を感じさせないコミュニケーションを実現する「スーパーコミュニケーション技術」を普及・推進することを目途に、現在、70社近い企業と、大学関係者80数名が会員になって参加している。
個人の知識をはるかに凌駕した200万語の知識を持つ「概念辞書」
―「概念辞書」とは、どのようなものなのでしょうか。
鳥澤端的に言いますと、膨大な単語を様々な意味的な関係で結んだものです。ある側面において、一個人の知識をはるかに凌駕したような知識をこの辞書は持っている。そういう辞書が現在できつつあるのです。
この「概念辞書」は我々が自分で書いて作るのではなく、Web上のテキストデータをスパコンでバリバリと処理して、自動で作るのです。この技術が、我々のウリです。広辞苑が大体25万語ですが、我々の辞書は現在約200万語をカバーしていますので、広辞苑の約8倍です。目標は250万語を想定して、ここ3年で何とか処理したいと思っています。
―250万というのは、ちょっと想像できない言語世界ですね。
鳥澤例えば「概念辞書」をブラウズするシステムに「洗濯機」と入れると、洗濯機に関するトラブルが出てきます。「水漏れ」「糸くず」「石鹸かす」などですが、どんどん広げていくと「アトピー」が出てくる。最初は、私も何のことか分かりませんでしたが、この概念辞書はWeb上の検索エンジンに直結されているので、それで調べてみると、洗濯機のカビがアレルギーの原因になるらしいと…。そこでアトピーの原因になる単語を概念辞書で調べると「ヒョウダニ」「ホルムアルデヒド」「重金属」「ハウスダスト」などが出てきて、ここに「カビ」も出てくる。
次に、カビの対策を概念辞書で調べてみると、「掃除」「整理整頓」と当たり前のものに続いて「銀イオン」や「ヒノキチオール」など意外なものも出てくる。こういうキーワードが洗濯機に関係していることを知っている人は、ごく少数でしょう。そういう意味で、概念辞書のデータは一個人の持つ知識をすでに凌駕してしまっているわけです。

―予想もしない展開が次々に出現するわけですね。
鳥澤もし私が電機メーカーの洗濯機開発者だとすれば、この辞書を見て、除菌に効くという「ヒノキチオール」に目がいくかもしれない。また、「銀イオン」という単語が表示されているので、これを参考にするかもしれない。そこに似た言葉として「銅イオン」が出ています。そこで「洗濯機、カビ、アトピー、銅イオン」で検索しますと、主婦向きの口コミサイトの中に、「洗濯ネットに10円玉を入れて洗濯機に入れておくとカビが生えない」という主婦の知恵に出くわす。こうしたことが新商品の開発に結びつくかもしれないということです。
また、仮に新製品を開発する場合、既存の製品の欠点、トラブルを網羅的に全部つぶしていく、これも1つ有効な戦略だと思います。ところがこれまでは、その分野で長く活動してきた人が、過去の経験に基づいて、既存の製品の欠点、トラブルを数え上げるしか手はなかった。しかし、概念辞書には、製品のWeb上で言われている欠点などがリストアップされており、欠点に対する対策までもが、ある程度網羅的に書かれています。これを出発点とすれば、新製品の開発のようなクリエイティブな作業も加速できるのではないかと考えているわけです。
―1つのキーワードからの発展が、様々な解答や新たな発見を生み出す可能性があるということですね。
鳥澤“意外だけれどひょっとしたら役立つかも知れない”という情報は、Webの中にいくらでもあるわけです。普通の検索エンジンの欠点は、どうしても人気のあるメジャーな話題中心で、検索する人は最初の10件くらいしか見ないですね。だから、「アトピー対策の洗濯機」を探そうとしても、なかなかたどり着けない。ところがこの「概念辞書」ならば、Web上の情報を要約した形で表示するので、そうした存在しているのかどうか分からないような情報でも、比較的簡単に見つけることができるわけです。
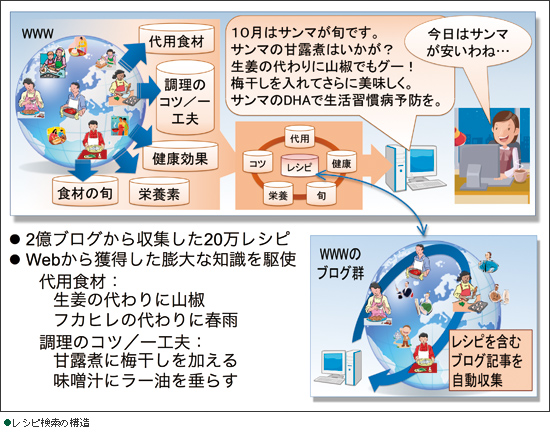
レシピ検索では2億件のブログから20万件のレシピを抽出
―「概念辞書」は既に使われているのですか
鳥澤はい。ニフティ(株)から受託研究をいただいておりまして、1つは「@nifty温泉」というサイトで、実際の業務として運営されています。もう1つは、まだベータ・バージョンですが、「@niftyみんなのレシピ検索」があります。
「@nifty温泉」では、そこに投稿された温泉に関するいろいろな口コミを分析・分類する辞書が必要で、例えば、湯の種類も「ナトリウム―炭酸水素塩」「単純泉」など専門用語が多く、また、料理などに関する言葉もいろいろ出てきますので、それらを分類するために私達の辞書が使われています。
レシピ検索では、投稿ベースのサイトが非常にポピュラーですが、我々の辞書は投稿を待つのではなく、既にいろいろなブログに書かれているレシピを自動的に集めています。現在、約2億件のブログ記事の中から20万件ほどレシピを集めており、それに対して検索ができるシステムを作っています。
そして、さらに一工夫して、例えば、フカヒレの代わりに春雨を使っても良いとか、味噌汁にラー油をたらすと味噌ラーメンみたいでおいしいとか…あまり普通の人達では思いつかないような料理に関する知識も概念辞書から提示して、より料理を楽しくすることを目指しています。
また、我々は単にレシピを検索するのではなく、「冷え性に効く料理」「美肌になるスープ」「メタボに効くイタリアン」と、レシピ以外の要素を入れた検索もできるようになっています。例えば、集めたレシピ・データに「冷え性」という言葉がどこにも出ていない場合、通常の検索なら「ヒットしませんでした」で終わりですが、我々の技術だと「ニンニクは冷え性に効く」という関係を取ってきてあるので、ニンニクを含むレシピを推薦できるのです。

―関連づけられたデータがどんどん蓄積されていくわけですね。
鳥澤我々の技術の特長は、例えば、AとBという単語の間に「AはBの対策である」といった関係が成立している、という例をいくつか示してやると、後は、そうした対策の関係を持つ単語の対をWeb上の大量のテキストから自動で高速に見つけるのです。
この過程で、例えば「AはBの対策である」というパターンと「BはAで防げる」というパターンは同じ意味を持っているということを自動で認識するといったことを行います。こうした同じ意味を持つパターンの対のことを我々は「言い換え」と呼んでいますが、これを自動認識するということは、90年代には夢の世界でした。しかしこれが、ある程度できるようになってきたのです。これが我々の研究のエキサイティングなところなのです。
―膨大な資料を集めることによって統計化・パターン化が進み、さらに膨大な資料を集めることが楽になるということですね。
鳥澤そうですね。正のスパイラルがだんだん描けるようになってきました。現状ではWebページは、5000万ページで動かしていますが、今年度中に6億ページに増やす予定です。また、1種類の関係を得るのに1時間くらいかけているのを30分くらいに短縮したい。これをALAGINでお使いいただこうと、日々セールスしています。
高度なロボットの誕生も期待できます。
―一種のパターンを認識するプログラムを作っているわけですね。
鳥澤私達の研究は、言葉の意味的な部分にまで立ち入っていて、普通のキーワード・サーチより一段上にあるのです。
将来的には辞書で終わるつもりは全くなくて、MASTARの他のグループと共同で、という話になりますが、ロボットが家庭の会話をモニターしていて、何かアドバイスをしてくれるような時代が来るだろうと思っています。
例えば、ロボットが、どうもここの家の夫婦は、アトピー性皮膚炎の子どもの事で悩んでいる、ということを認識していたとする。その状況で、洗濯機を買い換える話が夫婦の間に出た時に、ロボットが「カビとアトピーは関係あります。カビ対策を施したものを買ったほうがいいですよ」とアドバイスする。つまり常識を備えたロボット、それも主人の知らない常識を備えたロボットというわけです。
―言語資源に関係性が出てくると、考えることにもつながって、高度な能力を持ったロボットも登場するというわけですね。
鳥澤Web上の情報は、世界最大の情報と言えますが、整理されていないので知識とは呼べないのです。ところが我々の技術を使うとそれが組織化されて、知識と呼びうるものに変っていき、「概念辞書」に聞けばかなりのことに答えてくれるという世界が待っているだろうと考えています。
―「概念辞書」は、日本語だけですか。
鳥澤機械翻訳をやっているグループがありますから、それと組み合わせることで、外国語にも対応できると思っています。そうすれば世界の情報が早く入手できます。例えば、「ベビーカーの指挟み事故」といったWeb上の話題が日本に入って来るまでには、タイムラグがありますね。日本ではトラブルとして認識されていないのに、アメリカで認識されている。そういう情報を人に先んじて入手するというのは、企業などにとって有益ですよね。そのためには外国語版も作る必要があります。
―データベースは膨らむ一方だと思いますが、これにより世界的な規模での言語資源基地的なものが日本にできると考えていいわけですね。
鳥澤そうですね。MASTARプロジェクトは現在、5年計画の中の1年半を経過したところです。3年後にはそうした状況も見えてくると思います。そして、この研究開発を利用してどのようなサービスが出てくるか、企業にもお考えいただきたいのです。たぶん思いもしないサービスが出てくるのではないでしょうか。
―今日はどうもありがとうございました。

- 鳥澤 健太郎(とりさわ けんたろう)
- 知識創成コミュニケーション研究センター
MASTARプロジェクト 言語基盤グループ
グループリーダー - 東京大学大学院理学系研究科博士課程専攻中退後、同研究科助手。その後、科学技術振興事業団さきがけ研究21研究員(兼任)、北陸先端科学技術大学院大学助教授、准教授を経て、2008年NICTに、MASTAR プロジェクト言語基盤グループ、グループリーダーとして着任。自然言語処理、特にWeb上の言語処理の研究に従事。けいはんな連携大学院教授を兼務。博士(理学)