汎用・特許ユニバーサル翻訳モデルの公開
2025年7月17日
今回、国立研究開発法人情報通信研究機構(NICT、理事長: 徳田 英幸)では、「みんなの自動翻訳@TexTra」(https://mt-auto-minhon-mlt.ucri.jgn-x.jp)において、一つのモデルで複数の言語方向に対応できる自動翻訳モデル(ユニバーサルモデル)について、汎用と特許に対応した自動翻訳エンジンを公開しました。
背景
NICTでは、従来より自動翻訳エンジンを研究開発しており、2017年からは、ニューラル機械翻訳(NMT)により高精度な汎用エンジンや特許エンジンを構築してきました。これらのNMTは、高速・軽量であるものの、1エンジンにつき1言語方向(日英翻訳や英日翻訳などの片方向)のみに対応したものでした。そのため、取り扱う言語数が増えると、多数の翻訳エンジンを起動する必要がありました。また、対話用の翻訳エンジンについては、複数言語方向を1モデルで扱うユニバーサルモデルを開発していましたが、汎用や特許などの複雑な文章の翻訳には対応していませんでした。
成果
今回、大規模言語モデル(LLM)のアーキテクチャを採用し、複数言語を1モデルで翻訳可能な翻訳特化型汎用・特許ユニバーサルモデル(汎用は日本語・英語⇔多言語、特許は日本語⇔多言語)を研究開発しました。
下の2つの図では、それぞれ、汎用・特許について、多言語から日本語への翻訳の自動評価尺度BLEUスコア(※)を比較しています。汎用・特許UMと汎用・特許UMTがユニバーサルモデルで、汎用・特許NTは、従来からNICTで研究開発しているNMTです。
従来のNMTと、ユニバーサルモデルの大きな違いとしてパラメタ数があります。それぞれのパラメタ数を比較すると、汎用・特許UMTは1モデル当たり18億パラメタ程度、汎用・特許UMは1モデル当たり120億パラメタ程度です。一方、汎用・特許NTは1言語方向あたり8億パラメタ程度で軽量ですが、複数言語方向を扱うためには、言語方向数の翻訳モデル(エンジン)が必要になります。
一般に、パラメタ数が多いほど高精度の翻訳が可能となりますが、翻訳速度が遅くなるというトレードオフの関係があります。そのため、従来のNMTに加えて、翻訳特化型のユニバーサルモデルを勘案することで、必要な翻訳対象の言語数と利用可能な計算機環境に応じて、最適な翻訳エンジンを選択することが可能となります。
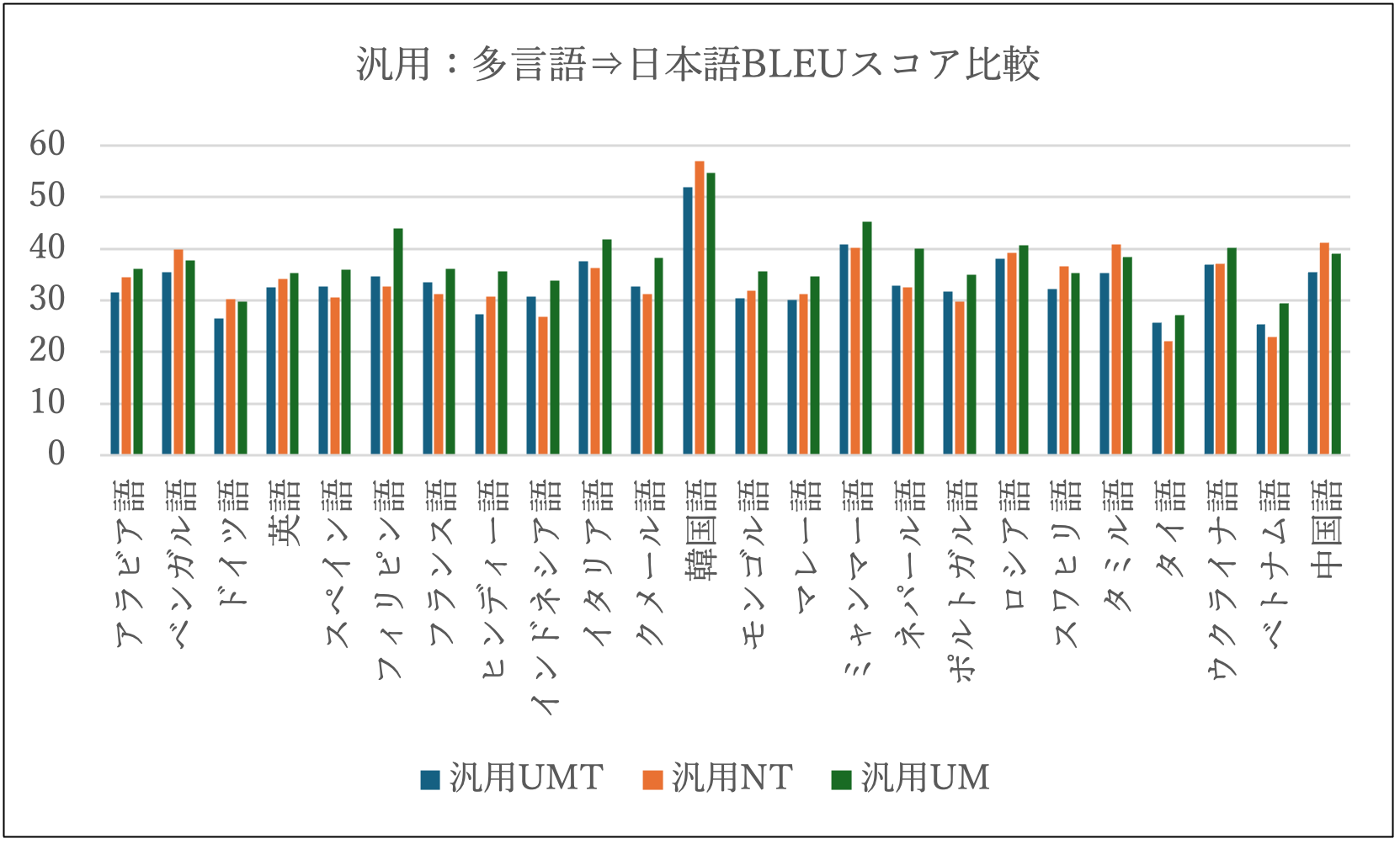
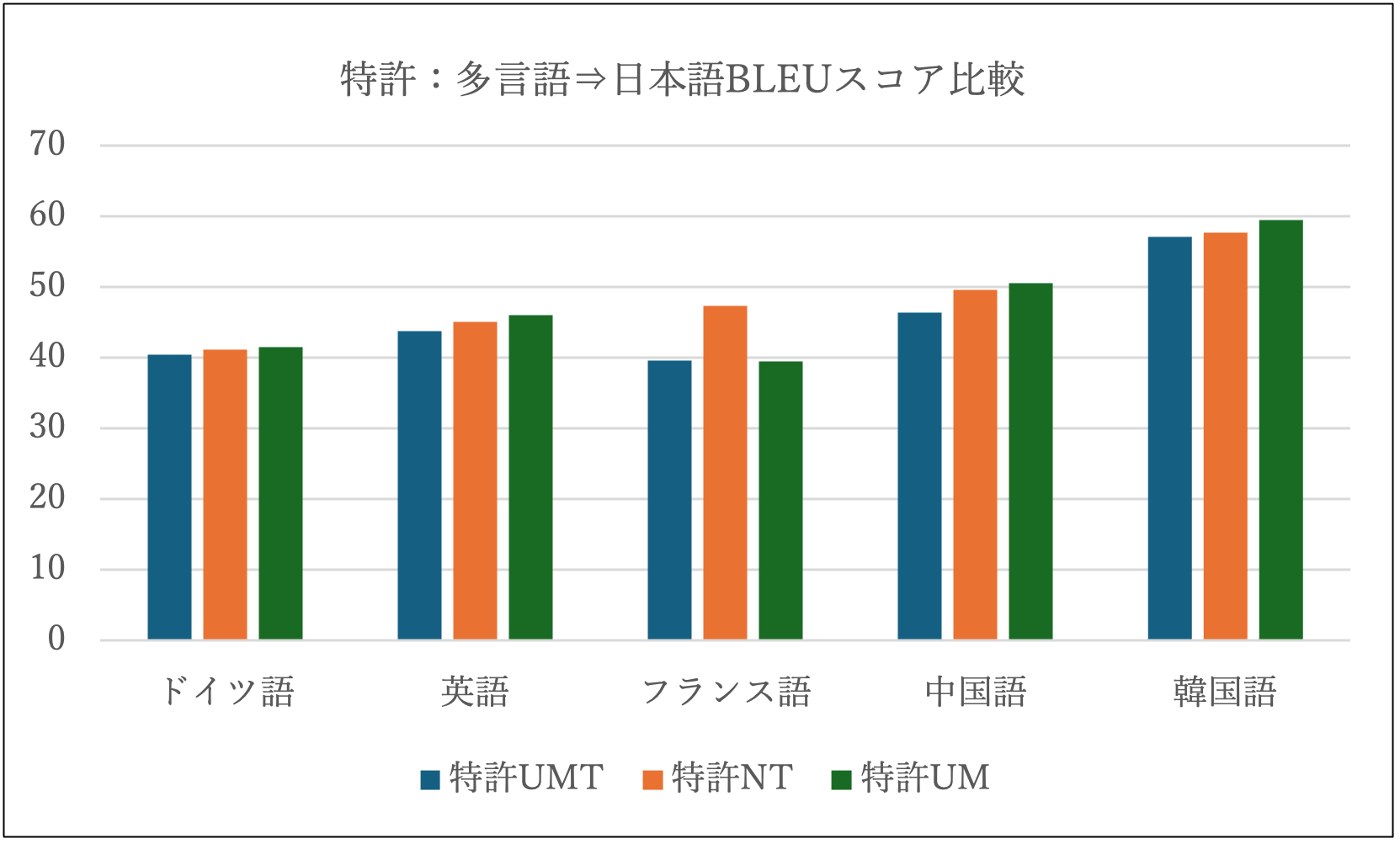
これらの図より、汎用・特許UMT < 汎用・特許NT < 汎用・特許UM、というBLEUスコアの関係にあることが分かります。また、汎用UMと汎用NTの出力を比較すると、次の文のような省略補完において、汎用UMの方が優れていることが多いです。
- 原文:
- 夫が足を怪我しましたが、病院に行った方が良いでしょうか。
- 汎用NT:
- My husband hurt his leg, should I go to the hospital?
- 汎用UM:
- My husband hurt his leg. Should I take him to the hospital?
※BLEUスコア:
自動翻訳文と人手による参照訳との類似度の一種であり、自動翻訳エンジンの比較に用いられる。BLEUスコアが20以上であれば、実用的な精度で使えることが多い。
今後の展開
今後は、研究開発したユニバーサルモデルを、同時通訳やテキスト翻訳で有効性を実証することを予定しています。また、今回研究開発したユニバーサルモデルでは、言語モデルのアーキクチャを活用していますが、翻訳に特化した自動翻訳モデルです。今後、大規模言語モデルの特質を活用し、翻訳が得意なLLMを目指して研究開発を進めてまいります。
問い合わせ先
先進的音声翻訳研究開発推進センター
先進的翻訳技術研究室
内山 将夫
E-mail: textra-info khn.nict.go.jp
khn.nict.go.jp
khn.nict.go.jp