日本語での論文検索:arXiv、PubMed にERIC、RePEcを追加
2025年6月11日
今回、情報通信研究機構(以下、NICTという。)では、英語論文データベースのarXivとPubMedに追加してERICとRePEcより文献情報をダウンロードし、タイトルと要約を日本語に自動翻訳してデータベース化し日本語と英語で検索できるようにしました。また、これらの文献データベース(2025年5月末時点で、arXiv は234万件、PubMedは2,734万件、ERICは192万件、RePEcは294万件)は適時追加更新しています。
背景
arXiv(https://arxiv.org/)は、著名なプレプリント(出版や査読前の論文)サービスです。また、PubMed(https://pubmed.ncbi.nlm.nih.gov/)は、主に医学文献を対象とした世界最大の文献データベースです。更に、今回追加したERIC(https://eric.ed.gov/)とRePEc(http://repec.org/)は、それぞれ、教育学分野および経済学分野の大規模な文献データベースです。一方、NICTでは、みんなの自動翻訳@TexTra(https://mt-auto-minhon-mlt.ucri.jgn-x.jp)という自動翻訳サービスを一般に公開しています。そして、従来より、汎用の翻訳エンジンに加えて、専門の翻訳エンジンを研究開発しており、その中でも学術文献の英日・日英翻訳に強い「サイエンス」翻訳エンジンを研究開発してきました。
成果
今回、NICTでは、arXiv、PubMed、ERIC、RePEcからダウンロードした文献のタイトルと要約を、サイエンス翻訳エンジンにより、全て和訳してデータベースを構築しました。また、それらを、みんなの自動翻訳@TexTraにおいて検索できるデモシステムを一般に公開しました。これらの重要文献データベースが、高精度な日本語で検索できることは利便性が非常に高いです。また、本デモシステムでは、論文検索APIも提供しているため、プログラムからの呼び出しも容易です。
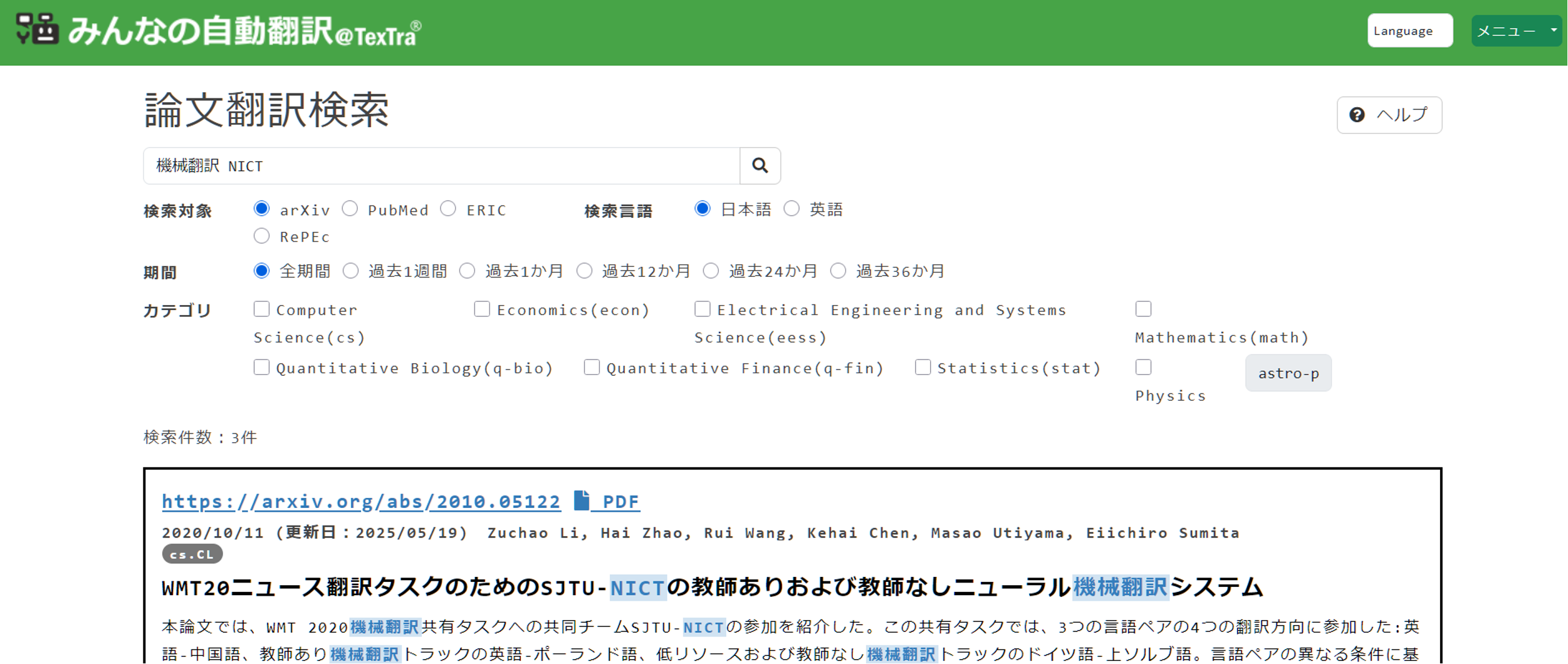
今後の展開
今回利用したサイエンス翻訳エンジンは、従来のニューラル機械翻訳によるものであり、タイトルや要約の機械翻訳には適していますが、論文全体の文脈を捉えた翻訳には能力が不足しています。今後は、大規模言語モデル等を活用することにより、論文全体を高精度に翻訳する自動翻訳エンジンを研究予定です。また、本論文検索デモシステムには、更なる分野のデータベースの追加を目標としています。
問い合わせ先
先進的音声翻訳研究開発推進センター
先進的翻訳技術研究室
内山 将夫
E-mail: textra-info khn.nict.go.jp
khn.nict.go.jp
khn.nict.go.jp