プライバシー保護連合学習技術「DeepProtect」「eFL-Boost」を活用した不正送金検知の実証実験を実施し、再現率向上を確認
ポイント
-
銀行3行と連携し、プライバシー保護連合学習技術「DeepProtect」と「eFL-Boost」を活用した不正送金検知の実証実験を実施
-
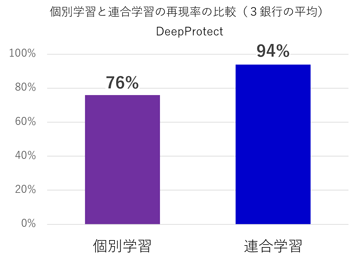
継続学習のシナリオを採用し、両連合学習技術で不正口座検知の再現率向上を確認
-
本研究で得た成果を基に他業種への展開を目指す
背景
今回の成果
[画像クリックで拡大表示]
今後の展望
各機関の役割分担
- NICT: DeepProtectの研究開発、実証実験計算基盤運用・保守、実証実験の運営・実施
- 神戸大学: eFL-Boostの研究開発、実証実験の企画・実施、データ解析
- エルテス: 実証実験の運営
- テラアクソン: 実証実験の企画・実施支援、データ解析支援、行内実証実験用システムの導入・実施
関連する過去のNICTのプレスリリース
- 2025年7月1日 放射線画像診断支援AIの実用化に向け高機能暗号を用いた異分野融合型の共同研究を開始
https://www.nict.go.jp/press/2025/07/01-1.html - 2025年6月10日 プライバシー保護連合学習技術「DeepProtect」を活用した銀行の不正口座検知の実証実験を実施し、検知精度向上を確認
https://www.nict.go.jp/press/2025/06/10-1.html - 2022年3月10日 プライバシー保護連合学習技術を活用した不正送金検知の実証実験を実施
https://www.nict.go.jp/press/2022/03/10-1.html - 2020年5月19日 プライバシー保護深層学習技術を活用した不正送金検知の実証実験において金融機関5行との連携を開始
https://www.nict.go.jp/press/2020/05/19-1.html - 2019年2月1日 プライバシー保護深層学習技術で 不正送金の検知精度向上に向けた実証実験を開始
https://www.nict.go.jp/press/2019/02/01-2.html
用語解説

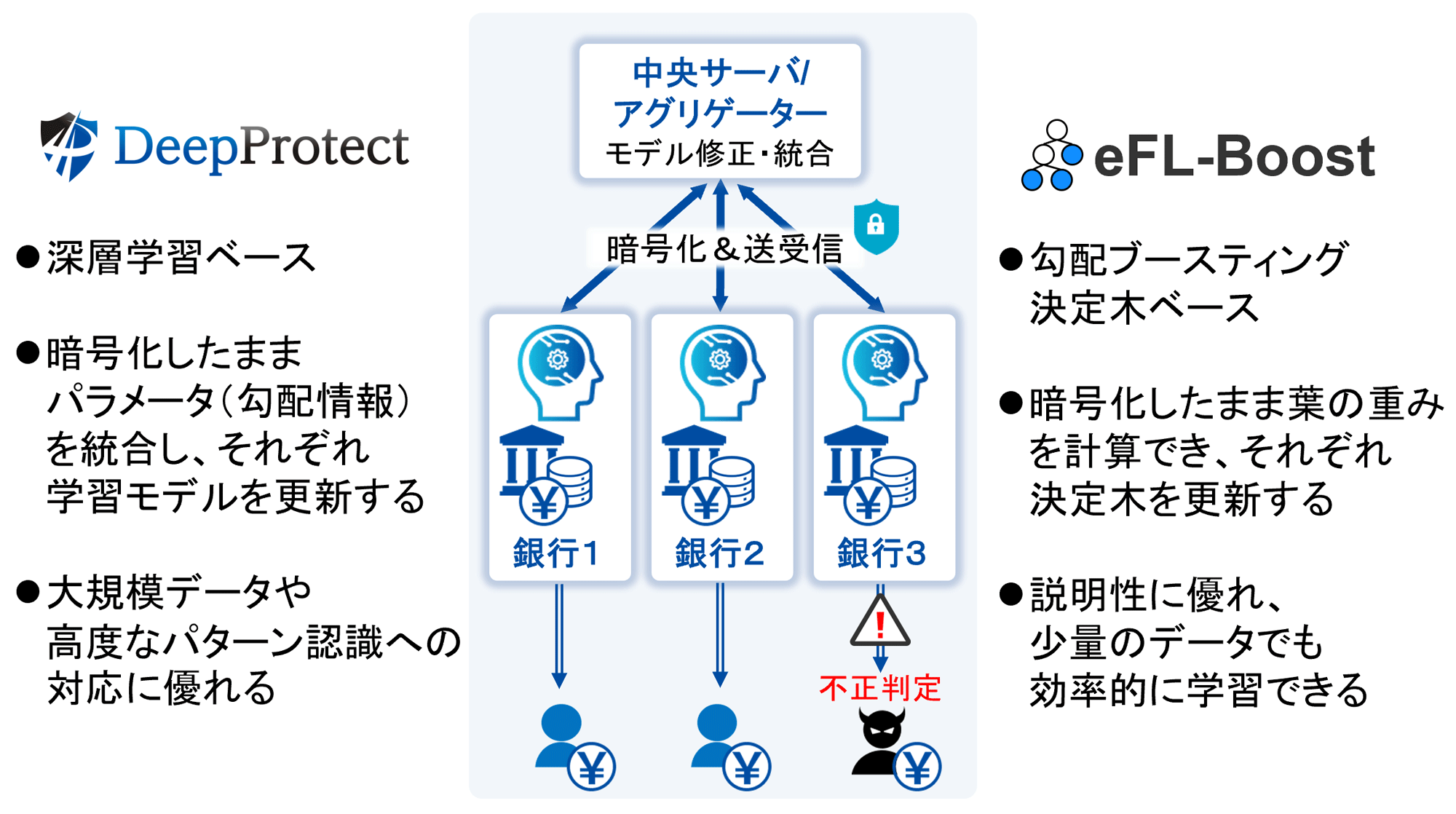
プライバシー保護連合学習技術「DeepProtect」
連合学習技術に暗号技術を融合することによって、NICTが独自に開発したプライバシー保護連合学習技術のこと。まず、各組織で持つデータを基に深層学習を行う際に、学習中のパラメータ(勾配情報)を暗号化して中央サーバに送り、中央サーバでは、暗号化したまま学習モデルのパラメータ(重み)の更新を行う。次に、更新されたこの学習モデルのパラメータを各組織においてダウンロードすることで、より精度の高い分析が可能になる。DeepProtectは、各組織から中央サーバにデータそのものを送ることなく、学習中のパラメータのみを暗号化して送信するが、このパラメータは、複数のデータを集計した統計情報とすることによって個人を識別できない状態にすることが可能であり、さらに、暗号化を施すため、データの外部への漏えいを防ぐことができる。
本技術により、パーソナルデータのような機密性の高いデータを外部に開示することなく、複数組織で連携して多くのデータを基にした深層学習が可能となる。eFL-Boostと比較して、大規模データや高度なパターン認識への対応に優れる。
本技術は、複数のジャーナルに採択・掲載されている[1,2]。また、動画による紹介を行っている[3]。
[1] L. T. Phong, Y. Aono, T. Hayashi, L. Wang, and S. Moriai, "Privacy-Preserving Deep Learning via Additively Homomorphic Encryption", IEEE Transactions on Information Forensics and Security, Vol.13, No.5, pp.1333-1345, 2018.
[2] L. T. Phong and T. T. Phuong, "Privacy-Preserving Deep Learning via Weight Transmission", IEEE Transactions on Information Forensics and Security, Vol.14, No.11, pp 3003-3015, 2019.
[3] 『NICTステーション 〜DeepProtect〜』
https://youtu.be/CpA9OD5vUIM
元の記事へ
[画像クリックで拡大表示]
継続学習 継続学習(Continual Learning) とは、機械学習モデルが新たなデータやタスクを継続的に学習しながら、既存のデータやタスクから得た情報・知識を保持したモデルを生成することを目的とした手法である。従来の機械学習では、全てのデータを一括して学習する「一括学習(batch learning)」が一般的であったが、実世界の多くの応用では、データが逐次的に到着するため、モデルが新規のデータの到着に順応し続けることが求められる。例えば、金融取引情報のように時系列で更新されるデータや、ユーザーの行動履歴が常に変化する状況においては、モデルが変化に即応して学習内容を更新する必要がある。継続学習は、こうした状況において忘却(catastrophic forgetting)を抑制しつつ、過去の知識を活かしながら新たな知識を蓄積することを可能にし、長期的な適応力を持つモデルの構築を支援する。 元の記事へ
再現率 実際に「不正」なデータの中で、モデルが「不正」と正しく予想できた割合を示す指標。再現率が高いほど、取りこぼしなく正しく検知できていることを意味する。再現率は、不正検出など「取りこぼしを減らすことが重要なケース」で重視される。 元の記事へ
適合率 モデルが「不正」と予測したデータの中で、実際に「不正」なデータである割合を示す指標。適合率が高いほど、誤検出が少なく、正確に予想できていることを意味する。適合率は、スパムメールの検出など「誤検出を減らすことが重要なケース」で重視される。 元の記事へ
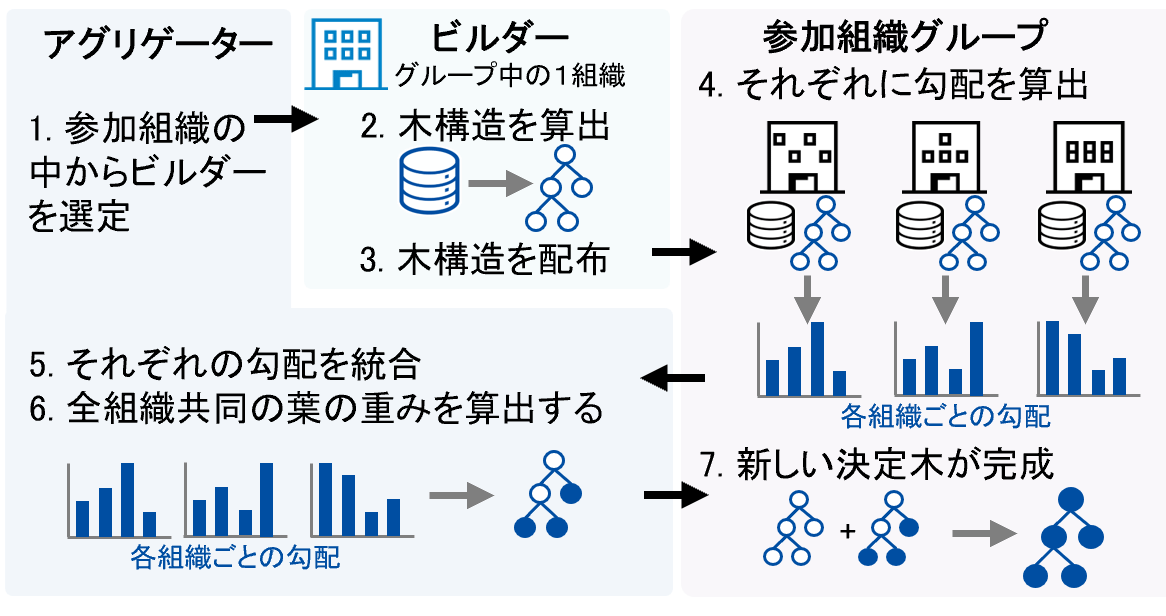
勾配ブースティング決定木 勾配ブースティング決定木(Gradient Boosting Decision Trees, GBDT)は、複数の決定木モデルを逐次的に構築・統合することで、高精度な予測を実現する機械学習手法である。単一の決定木では予測精度に限界があるが、GBDTでは各決定木が直前のモデルで生じた誤差を補うように設計されており、これを繰り返すことで予測誤差を徐々に修正し、モデル全体の性能を高めていく。GBDTは決定木を基盤としており、各木の貢献度や特徴量の重要度が明示的に計算できるという特徴がある。これは深層学習にはない特徴であり、深層学習と比較して出力結果の解釈がしやすいという利点を持つ。決定木は、「どの特徴量がどのような条件で予測に影響したのか」を分岐のルールとして明示的に示すため、人間にも直感的に理解しやすい構造になっている。また、GBDTは浅い決定木を繰り返し組み合わせて誤差を修正しながら学習を進める手法であるため、外れ値に対し頑強であり、大量のデータがなくても過学習を抑えつつ効率的に高い予測性能を発揮することができる。さらに、数値データに限らず、「はい/いいえ」やカテゴリ名といった非数値データを直接扱える実装が多く、実用性に優れた汎用的なアルゴリズムとして広く活用されている。 元の記事へ
本件に関する問合せ先
国立研究開発法人情報通信研究機構
サイバーセキュリティ研究所
セキュリティ基盤研究室
室長 小川 一人
 ml.nict.go.jp
ml.nict.go.jp国立大学法人神戸大学
数理・データサイエンスセンター
教授 小澤 誠一
kobe-u.ac.jp株式会社エルテス
IRI事業本部
リスクインテリジェンス部 基盤グループ
森 大樹
eltes.co.jp株式会社テラアクソン
代表取締役 研究責任者小澤 誠一
telaaxon.com広報(取材受付)
国立研究開発法人情報通信研究機構
広報部 報道室
nict.go.jp国立大学法人神戸大学
総務部 広報課
office.kobe-u.ac.jp株式会社エルテス
経営企画グループ 広報担当
eltes.co.jp株式会社テラアクソン
代表取締役 経営責任者安田 鉄平
telaaxon.com